데이터 입출력
할당(Assignment)
- 변수에 해당해당하는 값을 배정하는 것
- R에서는 =, <-, <<- 를 사용함.
- 할당된 객체는 메모리를 차지
- rm() : 불필요한 객체 처리
- edit() : 데이터 편집기 사용하기


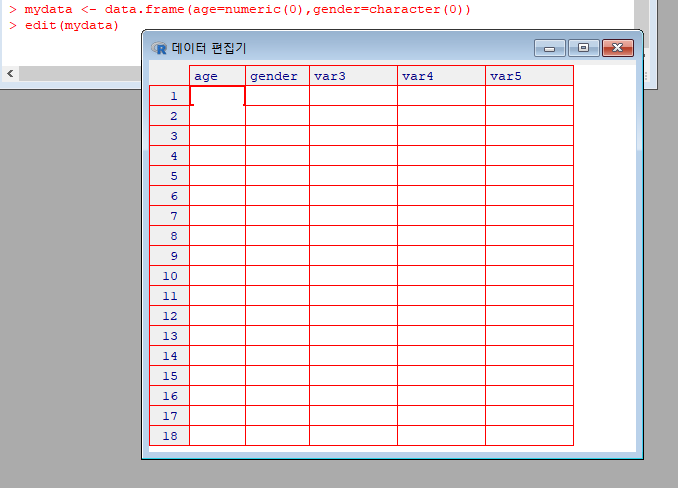
데이터 프레임(표)에서 데이터 하나 선택하기
> ars$mpg
[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2
[15] 10.4 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4
[29] 15.8 19.7 15.0 21.4데이터 프레임에 값 추가하기
> mydata <-women
> mydata
height weight
1 58 115
2 59 117
3 60 120
4 61 123
5 62 126
6 63 129
7 64 132
8 65 135
9 66 139
10 67 142
11 68 146
12 69 150
13 70 154
> attach(women)
> mydata$sum<-(height+weight)
> detach(mydata)
> mydata
height weight sum
1 58 115 173
2 59 117 176
3 60 120 180
4 61 123 184
5 62 126 188
6 63 129 192
7 64 132 196
8 65 135 200
9 66 139 205
10 67 142 209
11 68 146 214
12 69 150 219
13 70 154 224
14 71 159 230
15 72 164 236
> mydata$sum1 <- mydata$height + mydata$weight
> mydata
height weight sum sum1
1 58 115 173 173
2 59 117 176 176
3 60 120 180 180
4 61 123 184 184
5 62 126 188 188
6 63 129 192 192
7 64 132 196 196
8 65 135 200 200
9 66 139 205 205
10 67 142 209 209
11 68 146 214 214
12 69 150 219 219
13 70 154 224 224
14 71 159 230 230
15 72 164 236 236
데이터를 묶어서 변수로 저장하기
> x <- c(1,2,3,4,5) #X에 원하는 행렬(1,2,3,4,5) 삽입
> x
[1] 1 2 3 4 5
> x[2:3] #x에서 2~3번째 값 출력
[1] 2 3
> mean(x) #x 값들의 평균
[1] 3한 열의 평균구하기
> mean(women$height)
[1] 65
- 키보드 입력
- 직접 입력(command창) : 데이터프레임부터 생성 age <- c(25,30,56)
- R편집기를 이용
- > mydata <-data.frame(age=numeric(0), gender=character(0),weight=numeric(0))
- > mydata <- edit(mydata)
- 파일 불러오기
- > file()
- > url()
- 패키지를 이용 : Excel, 데이터베이스 XML, SPSS, SAS 등
- csv 파일 불러오기 (csv는 별도의 패키지 설치 없이 불러올 수 있음)
- > mydata <- read.table("'c:/fileName.csv", header=TRUE, sep='', , row.names="id")
- 데이터 내보내기
- > write.table(mydata, "c:/fileName.txt", sep="wt")
R에서 데이터의 종류
|
행 |
열 |
|
|
데이터베이스 |
Records |
Fields |
|
통계 |
Observation |
Variables |
|
기계학습(Mining) |
Examples |
attributes |
변수(Variable)의 종류
- 연속 수치형 : Continuous (nominal, ratio)
- 기수형(순서형) : Ordinal
- 명목형(범주형) : Nominal (Categorical)
- 기타 : 식별자(identifier), 날짜형(date)
데이터의 종류
- 숫자형(numeric) : 숫자(문자가 포함되어 있으면, 전체가 문자형 데이터로 변환)
- 문자형(character) : "", ''로 표시
- 논리형(logical) : True, False
- 복소수(허수, imaginary number)
- Raw(byte)
R에서의 데이터 타입
- vector : 1차원 배열, c(1,2,3,4,5)
- matrix : 2차원 배열
- array : 3차원 이상의 배열
- data frame : column마다 데이터의 형태가 다른 데이터(테이블)
- List : 서로 다른 데이터를 인위적으로 묶어놓은 것
- Class :
데이터셋
- 여러 데이터를 가지는 것
- 위 데이터를 data vetor로 저장할 때 c()를 이용
데이터 형태의 변환
- 데이터 형태의 확인
- is.numeric()
- is.character()
- is.vector()
- is.data.frame()
- is.matrix()
- 데이터 변환 함수
|
~로 변환 |
변환 함수 |
규칙 |
|
숫자형 |
as.numeric() |
false -> 0, "1" -> 1 |
|
논리형 |
as.logical() |
0 -> false, 그외는 true |
|
문자형 |
as.charcater() |
1,2 -> '1','2' |
|
범주형(factor) |
as.factor() |
|
|
1차원 배열(vector) |
as.vector() |
|
|
2차원 배열(matrix) |
as.matrix() |
|
|
3차원 이상 배열(data frame) |
as.dataframe() |
vector indexing : vector의 개별 항목은 첨자로 지정
> c(2,3) #2번째와 3번째 항목
> a <- a[-2] #2번째 항목을 제외
> a[2:4] #2번째부터 4번째 항목
연산자
> seq() : sequence 생성
> rep() : vector 항목의 반복
Vector 연산
- Recycling
- 서로의 개수를 맞춤
- c(1,2) + c(1,2,3)
- Filtering
- 조건이 충족되는 항목만 추출
- > z <- c(1,2,3,4,5)
- > w <- z[z>3] #z항목 중 3보다 큰 값들
- > w
- [1] 5 3
- N/A와 NULL
- N/A : missing Value 결측치
- Null : undefined value 적절한 값이 존재하지 않음
반응형