

Neo4j 그래프 데이터베이스 & 사이퍼

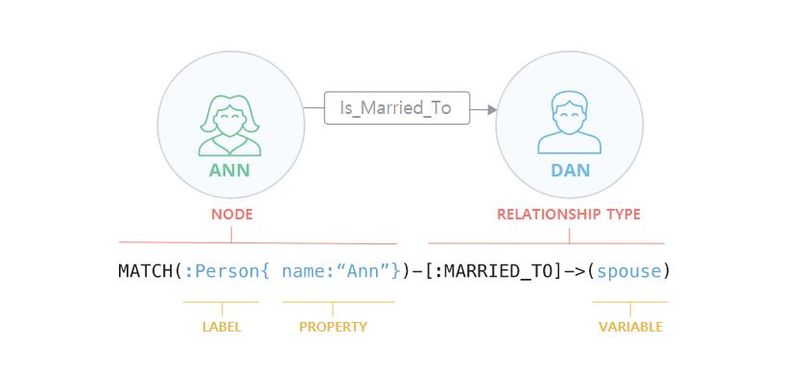
기본 데이터 구조는 위의 그림과 같습니다. 노드(개체)와 관계, 노드와 관계에 대한 속성, 노드를 묶는 단위는 라벨로 이루어져 있죠.
매뉴얼을 보면 다음과 같이 설명합니다.
노드Nodes | 관계Relationships |
데이터 개체 Nodes are the main data elements 관계로 다른 노드들과 연결 Nodes are connected to other nodes via relationships 하나 이상의 속성을 지님 Nodes can have one or more properties (i.e., attributes stored as key/value pairs) 하나 이상의 라벨을 지님 Nodes have one or more labels that describes its role in the graph |
두 개의 노드를 연결 Relationships connect two nodes 직접적으로 연결 Relationships are directional 하나의 노드가 여러 개의 관계, 재귀적인 관계도 가질 수 있음 Nodes can have multiple, even recursive relationships 관계는 하나 이상의 속성을 가진다 Relationships can have one or more properties (i.e., attributes stored as key/value pairs) |
속성Properties | 라벨Labels |
문자로 정의된 값 Properties are named values where the name (or key) is a string 색인화되고, 제한될 수 있다. Properties can be indexed and constrained 다양한 속성으로 복합적인 색인을 만들 수 있다 Composite indexes can be created from multiple properties |
노드를 묶는 단위 Labels are used to group nodes into sets 하나의 노드는 여러개의 라벨을 가질 수 있다 A node may have multiple labels 그래프에서 노드를 더 잘 찾을 수 있도록 색인화된다 Labels are indexed to accelerate finding nodes in the graph 기초 라벨 색인은 속도에 최적화되어 있다 Native label indexes are optimized for speed |
- A -[:Knows]-> B : Knows 관계를 가진 A와 B
- A -[*]-> B : 관계를 가진 A와 B
- A --> B : 관계를 가진 A와 B
- A -[*1..3]-> B : 1~3의 거리를 가진 A와 B
- A -[:Knows*1..3]-> B : Knows관계의 거리가 1~3인 A와 B
- A -[:Knows{since:2009}]-> B : Knows관계를 가지고 since 속성이 2009값을 가지는 A와 B
- Where A.name="ooo": name 속성의 값이 ooo인 노드 A
- Where A.name in ["aaa", "bbb", "ccc"]: name 속성이 값이 aaa, bbb, ccc 중 하나의 값을 가지는 노드 A
- Where A.name starts with "A": name 속성의 값이 A로 시작하는 노드 A (SQL의 where name like 'A%')
- Where A.name ends with "A": name 속성의 값이 A로 끝나는 노드 A (SQL의 where name like '%A')
- Where A.name contains "A": name 속성의 값에 A가 들어가는 노드 A (SQL의 where name like '%A%')
RETURN은 보고 싶은 형태를 지정해줄 때 쓰는 단어입니다. 앞서 검색한 것들은 모두 보고 싶다거나, 검색된 개체 중 특정 속성만 보고 싶다거나, 검색된 개체의 개수를 보고 싶다거나 할 때 말이죠. 이 부분은 뒤의 예시문에서 확인해보시면 될 것 같아요.
그리고 데이터 자체를 생성 및 삭제를 할 수 있는 단어인 CREATE와 DELETE/ 노드를 수정하는 단어인 SET과 REMOVE는.. 간단히 예시문으로 보여드릴게요.
CREATE
CREATE (ee:Person { name: "Emil", from: "Sweden", klout: 99 })
- CREATE (js:Person { name: "Johan", from: "Sweden", learn: "surfing" }), (ir:Person { name: "Ian", from: "England", title: "author" }), (js)-[:KNOWS {since: 2001}]->(ir)
| 함수명 | 기능설명 | 사용예시 |
|---|---|---|
| collect() | 특정 조건으로 노드를 그룹화하고 그 한 그룹에 속하는 노드의 목록을 보여줌. | MATCH (n:person) RETURN collect(n.sex), n.name |
| count() | 노드의 갯수, (SQL의 count) | MATCH (n:person) return n.sex ,count(n) |
| exist() | ()안의 특정 값이 있는 경우 (SQL의 where is not null) | MATCH (p:Person) WHERE exists(p.firstname) RETURN p |
| none() | ()안의 특정 값이 없는 경우 (SQL의 where is null) | MATCH (p:Person) WHERE none(p.firstname) RETURN p |
| min(), max(), sum() | ()안의 값의 최소값, 최대값, 합계 | |
| length() | 노드와 노드 사이의 거리 (관계를 정의할때 *를 적어주어야 함. 그렇지 않으면 length의 값이 모두 1로 나옴(관계정의의 기본 단계값이 1이기 때문에 여러 단계의 관계를 보고 싶을때는 *를 써줌). | MATCH P=(A:Person) -[:Knows*]-> (B:Person) RETURN length(P) |
| shortestPath() | 노드와 노드 사이의 가장 빠른 길 | MATCH P=shortestPath((A:Person{name:'AA'}) -[*]-> (B:Person{name:'BB'})) RETURN P |