기본 함수
수학함수
|
함수 |
설명 |
|
abs(x) |
절대값 |
|
sqrt(x) |
제곱근 |
|
ceiling(x) |
x보다 작지 않은, x와 가장 가까운 정수 ceiling(3.475) = 4 |
|
floor(x) |
x보다 크지 않은, x와 가장 가까운 정수 floor(3,475) = 3 |
|
trunc(x) |
내림. trunc(4.78) = 4 |
|
round(x, digits=n) |
소숫점 n자리수까지 반올림. round(3.475, digits=2) = 3.48 |
|
cos(x), sin(x), tan(x) |
삼각함수 |
|
log(x) |
자연 로그 |
|
log10(x) |
상용 로그 |
|
exp(x) |
e^x |
|
factorial(x) |
팩토리얼 |
확률함수
특정 분포로 부터 난수를 발생시켜 이를 확률 표본으로 생성
확률함수의 종류
- d : 확률밀도함수
- p : 누적확률
- q : 4분위수
- r : 난수
|
함수 |
설명 |
|
dnrom(x) |
정규밀도함수 |
|
pnorm(x) |
누적 정규 확률 |
|
qnrom(x) |
정규 분포상의 x 분위수의 값 |
|
rnorm(n,m=0,sd=1) |
n개의 장규편차( 평균 m, 표준편차 sd) |
|
dbinom(x, size, prob) pbinom(q, size, prob) qbinom(p, size, prob) rbinom(n, size, prob) |
이항분포(size=표본수,prob=확률) |
|
dpois(x,lamda) ppois(1,lamda) qpois(p,lamda) rpois(n,lamda) |
poisson 분포(m=std=lamda) lamdd=4일때의 0,1 or 2 event가 발생할 확률 -> dpois(0:2, 4) |
|
dunif(x,min=0,max=1) punif(q,min=0,max=1) qunif(p,min=0,max=1) runif(n,min=0,max=1) |
일양분포 (unifrom distributions) |
통계함수
통계함수에서는 na.rm 옵션을 통해 결측치 제거 후 작업
|
함수 |
설명 |
|
mean(x,trim=0,na.rm=FALSE) |
x의 평균 결측치 제거 및 상하위 점수 5% |
|
sd(x) |
x의 표준편차 |
|
var(x) |
x의 분산 |
|
mad(x) |
평균 절대 편차 |
|
median(x) |
중간값 |
|
quantile(x, probs) |
x는 데이터 probs는 원하는 분위수의 범위 x의 30번째와 84번째의 분위수 quantile(x, c(0.30, 0.83)) |
|
range(x) |
범위 |
|
sum(x) |
합계 |
|
diff(x, lag=1) |
lagged differences |
|
min(x) |
최소값 |
|
max(x) |
최대값 |
|
scale(x, center=TRUE, scale=TRUE) |
데이터 정규화 |
기술통계
요약통계 sapply()
각종 그래프를 활용
기타 함수
summary(mydata) : 평균, 중위값, 1사분위/3사분위, 최소, 최대
히스토그램 Histograms
- hist(x)
- x는 plotting 하려는 값의 숫자 vector
- freq = FALSE option : 빈도 대신 확률 밀도
- breaks = option : bin의 개수 지정
- Histogram의 단점
- 구간 개수에 크게 영향을 받음
밀도 함수: plot(density(x))
> plot(density(mtcars$mpg))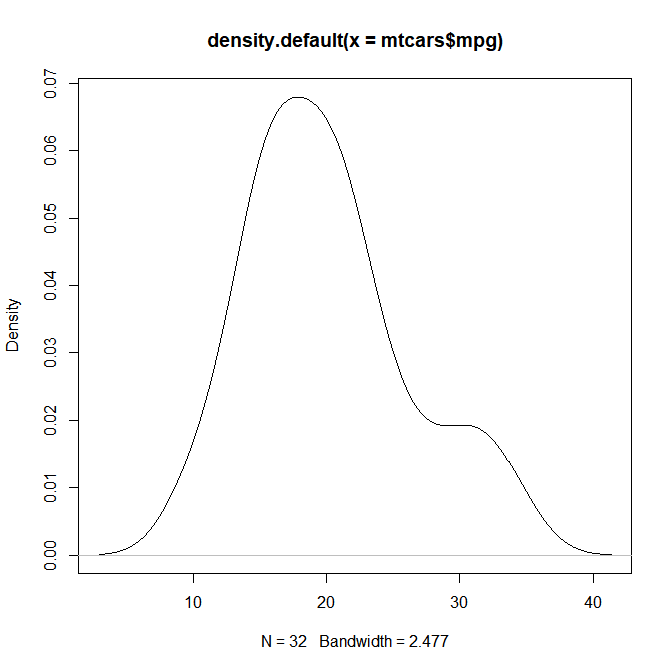
빈도수와 분할표
- 빈도표 생성
- table() : 빈도표
- prop.table() : 비율테이블
- margin.table() : marginal 빈도
- 분할표
- 각 개체의 특성에 따라 분류한 자료 정리표
- 2-way contingency table 2원 분할표 행과 열 변수간의 자료정리
상관관계
cor() : 상관관계, cor(x, use=, method=)
cov() : 공분산
|
option |
설명 |
|
x |
matrix 또는 data frame |
|
use |
결측치 처리방법 all.obs : 결측치가 없는 것을 전제 - 결측치 발생 시 에러 발생 complete.obs : 결측치 모두 제거(listwise deletion) pairwise.complete.obs : 상황에 따라 결측치 제거(pairwise deletion) |
|
method |
분석하려는 상관관계의 종류 : pearson ,spearman,kendall |
cor(x,y), rcorr(x,y) : column x와 column y의 상관관계
> x <- mtcars[1:3]
> y <- mtcars[4:6]
> cor(x,y)
hp drat wt
mpg -0.7761684 0.6811719 -0.8676594
cyl 0.8324475 -0.6999381 0.7824958
disp 0.7909486 -0.7102139 0.8879799
회귀분석
- 독립변수(x)와 종속변수(y)의 관계식을 구하는 것
- 단순회귀분석
- 한개의 독립변수(설명변수)로서 1차 선형 관계식을 구하는 것
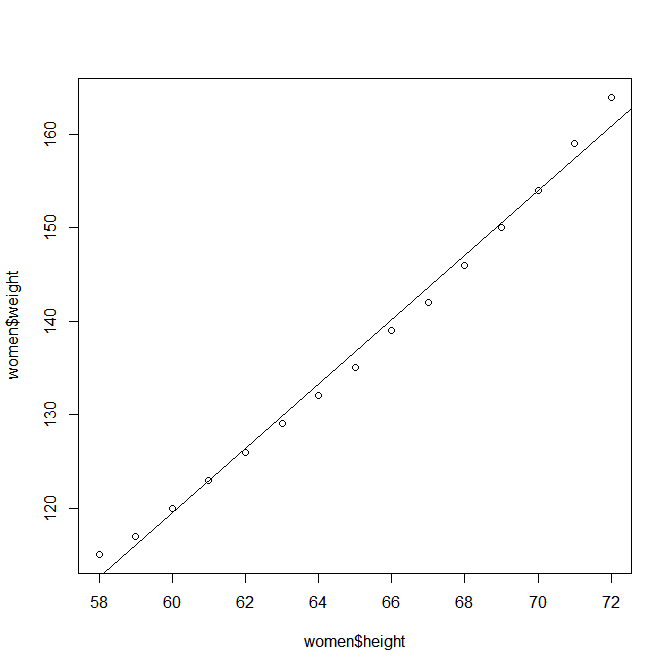
> data(women)
> fit <- lm(weight~height, data=women) #weight와 height의 상관관계 분석
> summary(fit)
Call:
lm(formula = weight ~ height, data = women)
Residuals:
Min 1Q Median 3Q Max
-1.7333 -1.1333 -0.3833 0.7417 3.1167
Coefficients:
Estimate Std. Error t value
(Intercept) -87.51667 5.93694 -14.74
height 3.45000 0.09114 37.85
Pr(>|t|)
(Intercept) 1.71e-09 ***
height 1.09e-14 ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.525 on 13 degrees of freedom
Multiple R-squared: 0.991, Adjusted R-squared: 0.9903
F-statistic: 1433 on 1 and 13 DF, p-value: 1.091e-14
> plot(women$height, women$weight)
> abline(fit)